
文字コード(もじコード)とは、コンピュータ上で各文字に割り当てられるバイト表現のことです。
IT、ソフトウェアを扱っていて、よくあるトラブル、不具合の一つに文字コードの違いがあります。
例えば、Windows版のエクセルでは、シフトJISの文字コードを前提としているために、UTF-8で書かれたCSV (Comma-Separated Values、コンマ区切り文字列) を読み込もうとすると文字化けしてしまいます。
それでは、どんな文字コードがあるか調べてみました。
ASCII (アスキー)
ASCII (アスキー、American Standard Code for Information Interchange)とは、現代英語や西ヨーロッパ言語で使われるラテン文字を中心とした文字コードです。
コンピュータその他の通信機器において最もよく使われているものです。
EBCDIC (エビシディック)
EBCDIC (Extended Binary Coded Decimal Interchange Code、エビシディック、拡張二進化十進コード) はIBMにより定義された、8ビットの文字コードです。
IBMのメインフレームで使用されています。
Shift JIS (シフトジス)
シフトJISとは、日本語を表示するために1文字ずつに番号を割り当てた、文字コードのひとつです。
Windows パソコンで標準の日本語用の文字コードとして使われています。
JIS規格で定められたJISコードを改良したもので、JISコードが7ビットで文字を表すのに対して、シフトJISコードは、すべての文字を2バイト (16ビット) で表します。
EUC (EUC-JP)
EUC-JP (Extended UNIX Code Packed Format for Japanese、日本語EUC) とは、UNIX上で日本語の文字を扱う場合に、最も多く利用されている文字コードです。
Unicode ユニコード
Unicode (ユニコード) とは、符号化文字集合や文字符号化方式などを定めた、文字コードの業界規格です。
Unicodeは全世界共通で使えるように、世界中の文字を収録する文字コード規格であり、文字集合、文字セットが、単一の大規模文字セットであること (「Uni」という名はそれに由来する) などが特徴です。
ローマンアルファベット、ギリシャ文字、ひらがな、絵文字、ハングル文字、アラビア文字なども同一の文字コードで扱うことが出来ます。
UTF-16
UTF-16 (UCS/Unicode Transformation Format 16) とは、Unicodeの、符号化形式および符号化スキームのひとつです。
UTF-16符号化形式のための文字符号化スキームには、UTF-16の他にUTF-16BE(ビッグエンディアン)、UTF-16LE(リトルエンディアン)があります。
Unicode ユニコードと言う場合、UTF-16のことを指す場合もあります。
UTF-8
UTF-8 (ユーティーエフはち、ユーティーエフエイト) とは、Unicodeで使える8ビット符号単位の文字符号化形式及び文字符号化スキームです。
特徴は次の通りです。
- ASCIIに対して上位互換となっている。
- ASCII互換部分は1バイトである反面、漢字や仮名などの表現に3バイトを要する。
- バイト単位の入出力を行うため、バイト順の影響がない。
パソコンで文字コードの変換方法
シフトJIS、EUC、UTF-8などで文字コードの変換が必要な事がしばしば起きますね。
Windowsパソコンで変換方法する方法は、次の通りです。
サクラエディターでテキストファイルを開き、
全選択した後で
「変換」⇒「文字コードの変換」を選びます。
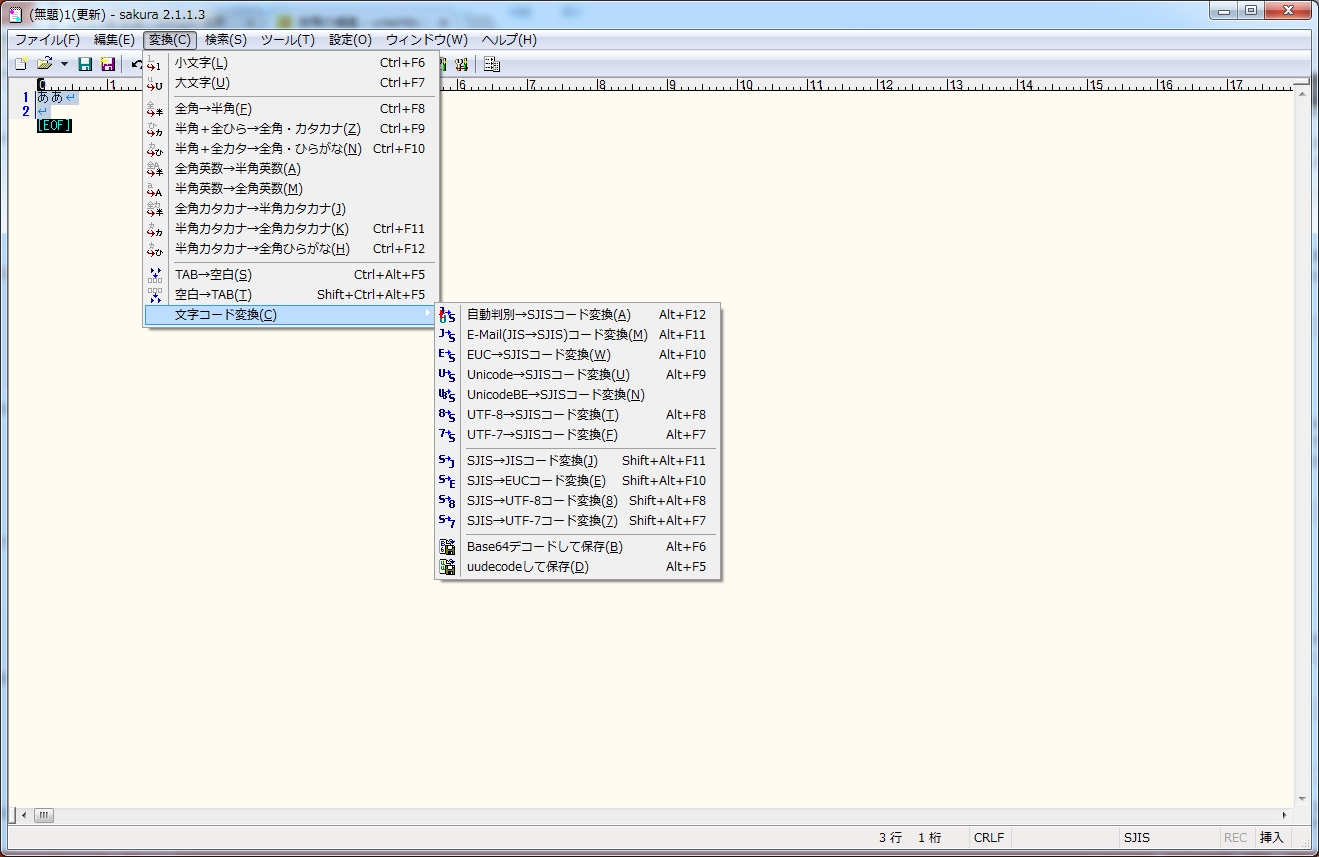
サクラエディターでは、
- EUC
- JIS
- SJIS
- Unicode (UTF-16)
- UTF-8
- UTF-7
の文字コード間で変換が可能です。
まとめ
Windowsパソコンでは、しばらくシフトJISを使っていくんでしょう。
ただ、今後の主流は、UTF-8です。


コメント